|
I am Naoto Inoue (井上 直人). |

|
|
[Feb. 2026] One paper is accepted to ICLR2026. Another paper is accepted to WACV2026. |
|
|

|
Kota Yamaguchi, Yizhi Wang, Naoto Inoue, Mayu Otani, Xueting Wang, CVPR Workshops, in conjunction with CVPR2024 project |
|
|
|
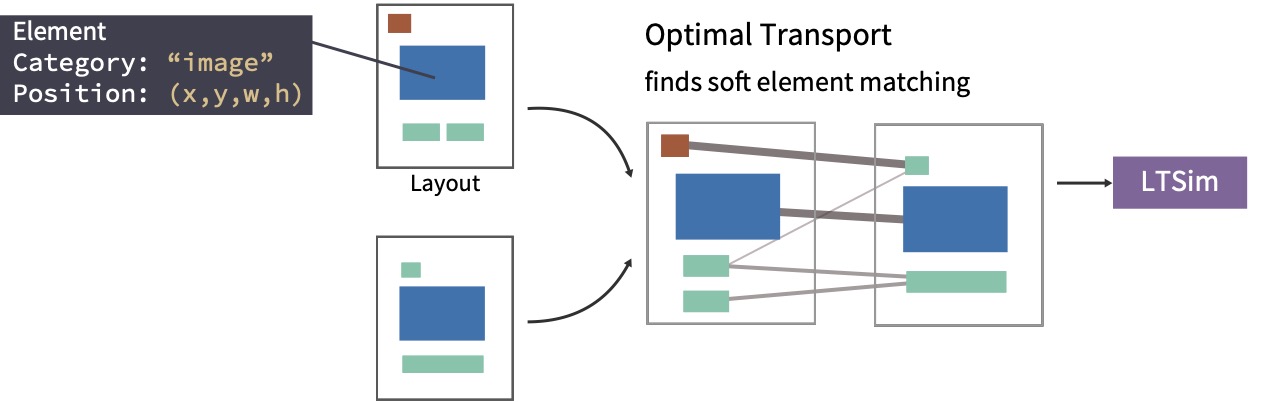
Mayu Otani, Naoto Inoue, Kotaro Kikuchi, Riku Togashi arxiv 2024 paper |
|
|
|
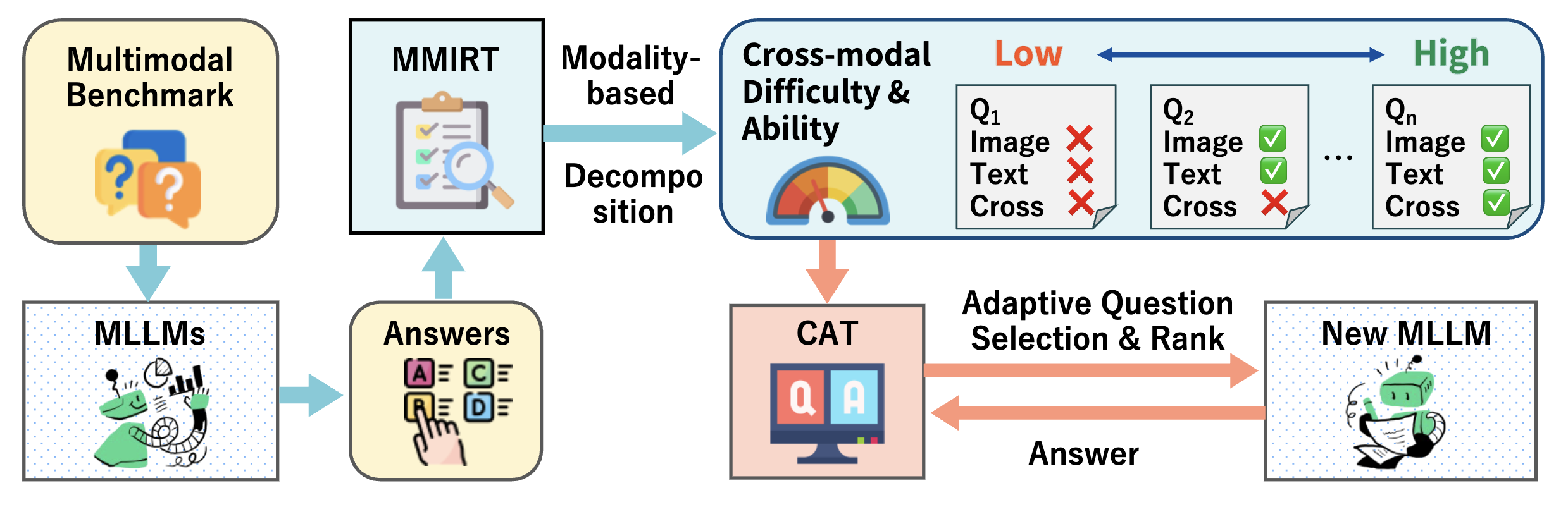
Shunki Uebayashi, Kento Masui, Kyohei Atarashi, Naoto Inoue, Bao Han, Hisashi Kashima, Mayu Otani, Koh Takeuchi ICLR 2026 paper |
|
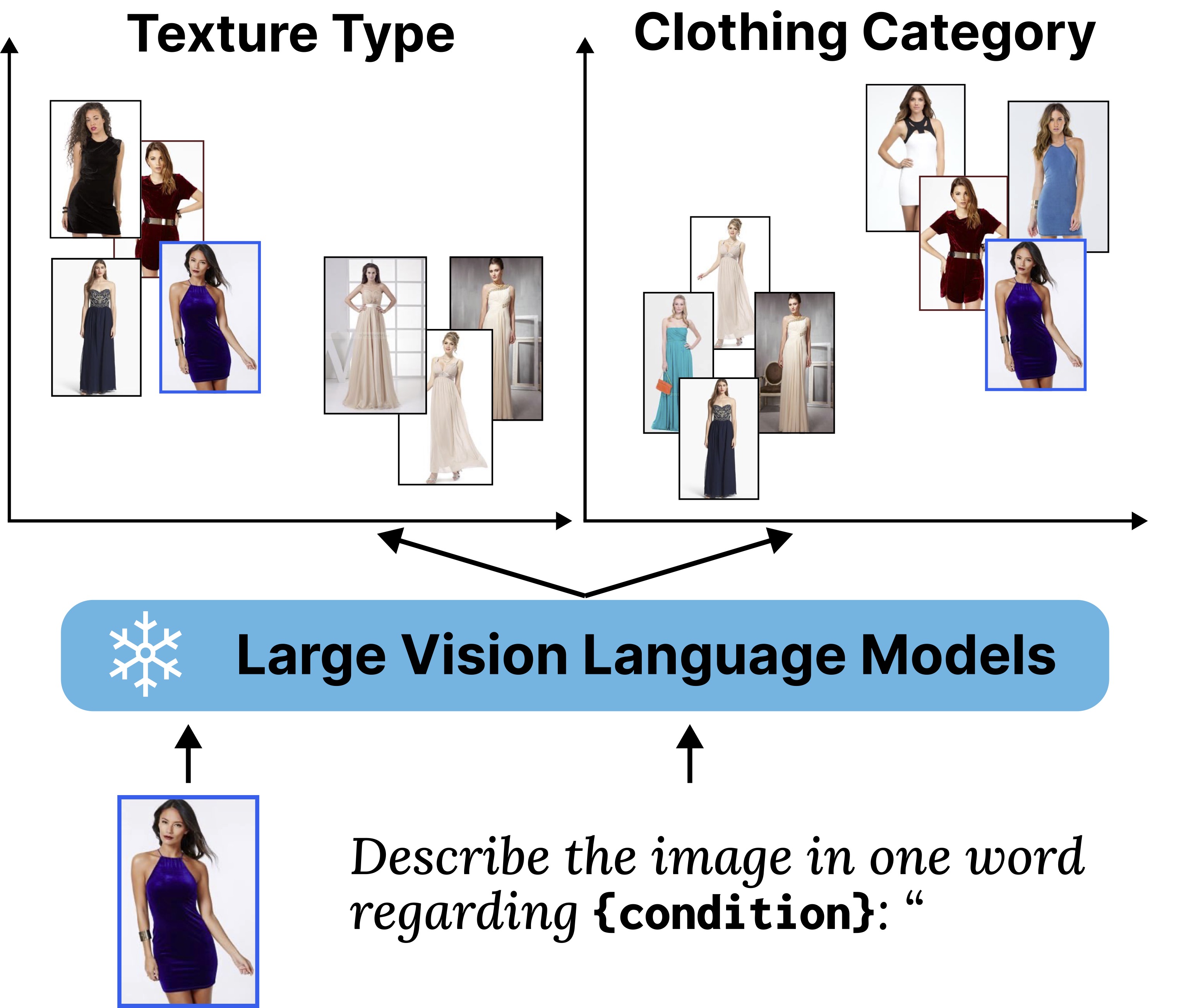
Masayuki Kawarada, Kosuke Yamada, Antonio Tejero-de-Pablos, Naoto Inoue WACV 2026 paper / code |

|
Kotaro Kikuchi, Naoto Inoue, Mayu Otani, Edgar Simo-Serra, Kota Yamaguchi ACMMM 2025 project / paper / code |
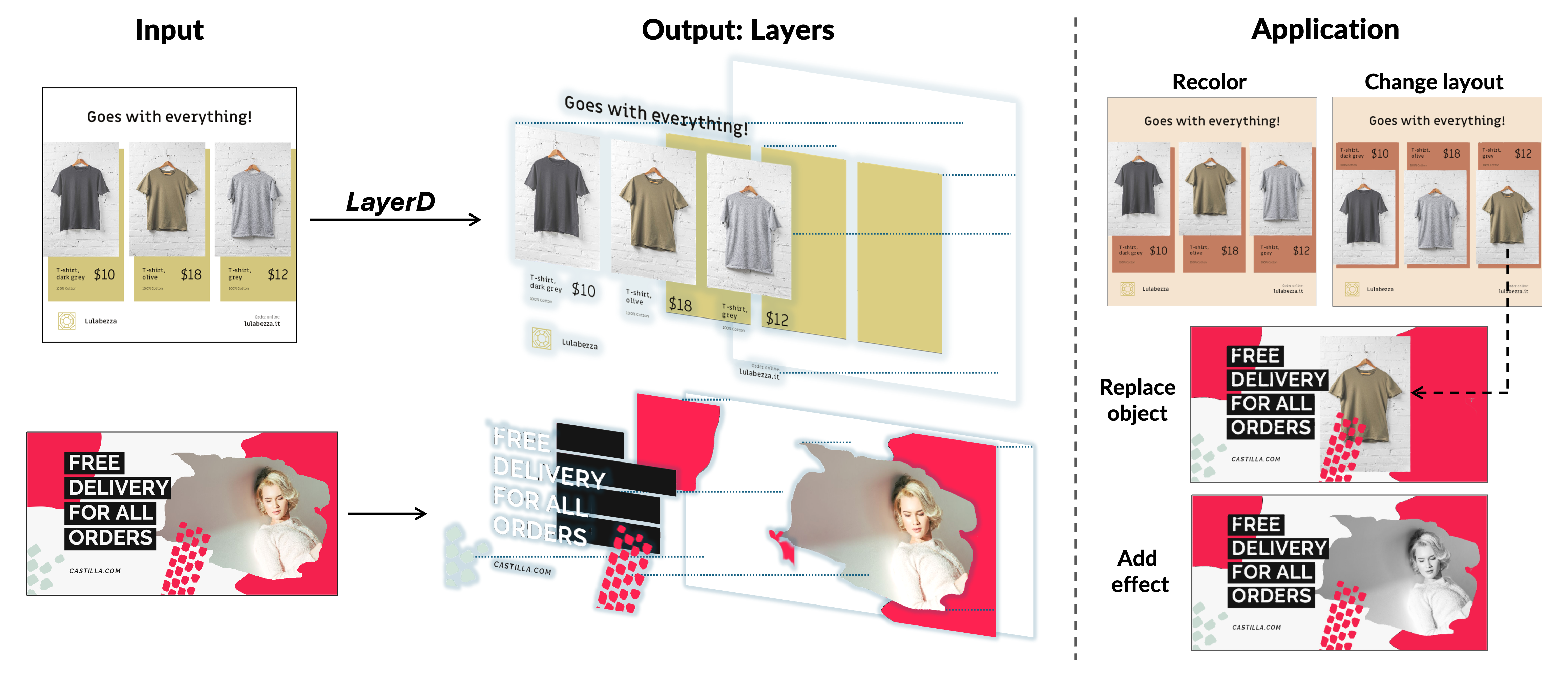
|
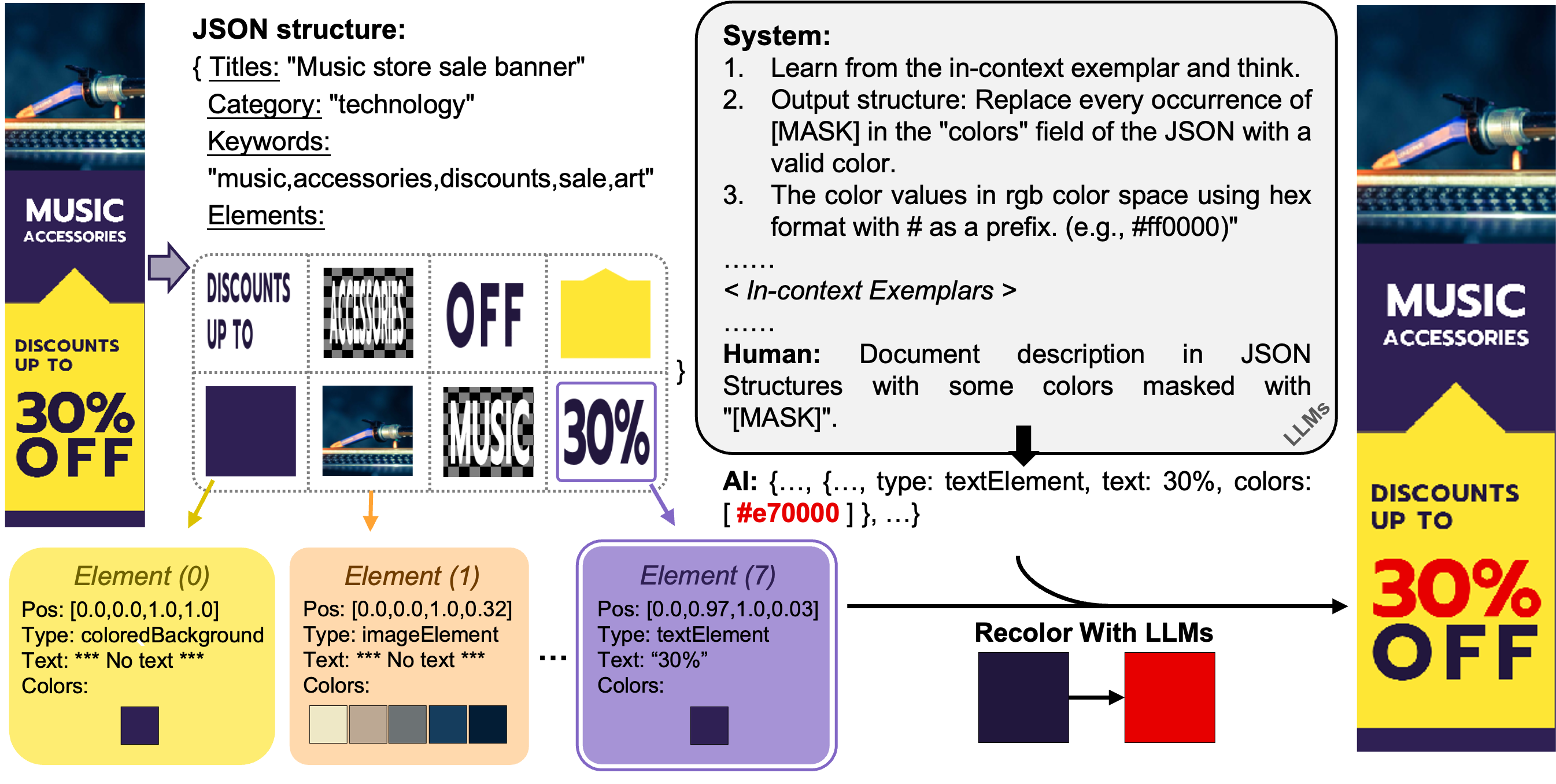
Tomoyuki Suzuki, Kang-Jun Liu, Naoto Inoue, Kota Yamaguchi ICCV 2025 project / paper / code |
|
Ding Xia, Naoto Inoue, Qianru Qiu, Kotaro Kikuchi ICDAR 2025 paper |
|
|
Wataru Shimoda, Naoto Inoue, Daichi Haraguchi, Hayato Mitani, Seiichi Uchida, Kota Yamaguchi CVPR 2025 highlight project / paper / code |

|
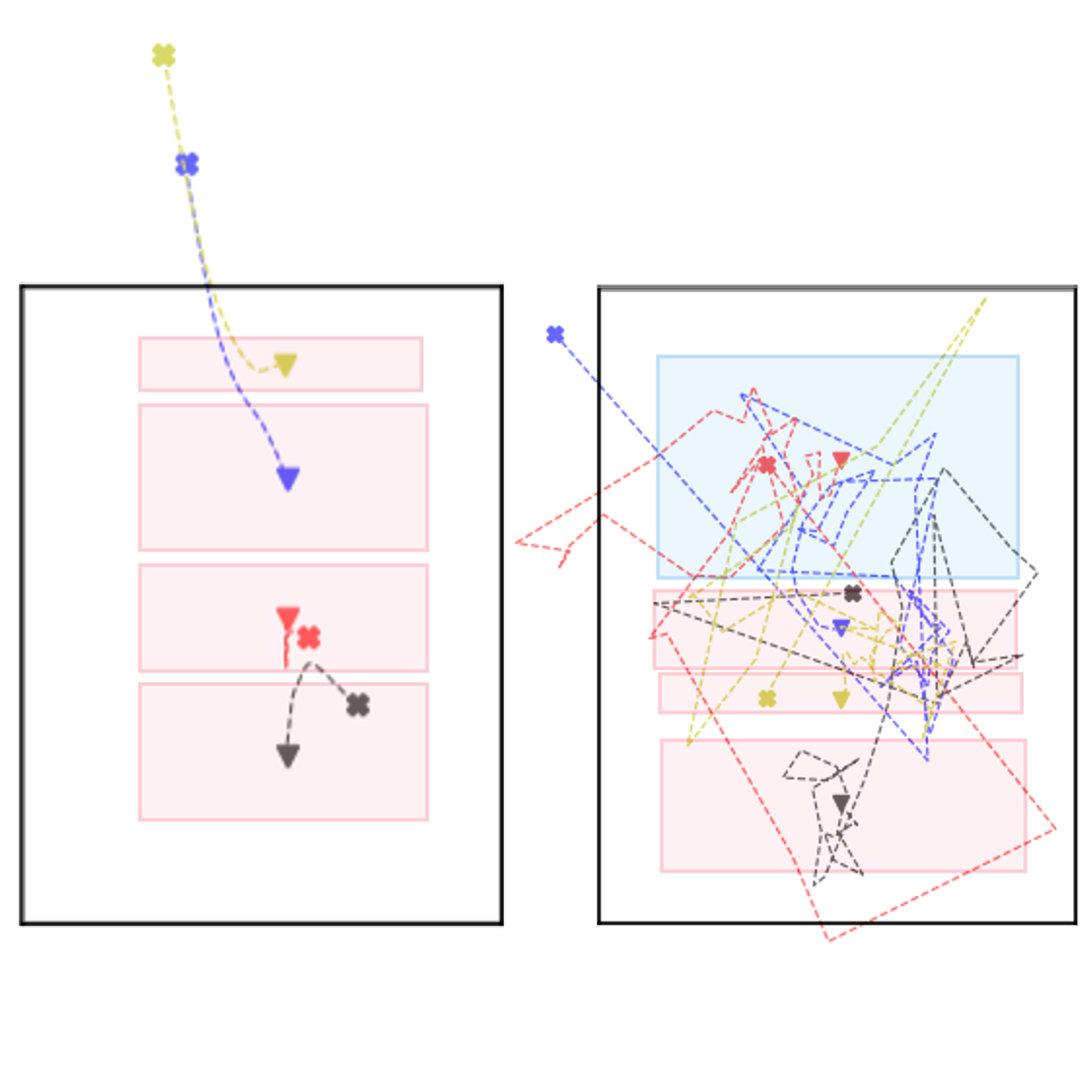
Daichi Haraguchi, Naoto Inoue, Wataru Shimoda, Hayato Mitani, Seiichi Uchida, Kota Yamaguchi SIGGRAPH ASIA technical communications 2024 project / paper / code |
|
Julian Jorge Andrade Guerreiro, Naoto Inoue, Kento Masui, Mayu Otani, Hideki Nakayama ECCV 2024 project / paper / code |

|
Naoto Inoue*, Kento Masui*, Wataru Shimoda*, Kota Yamaguchi (*: equal contribution) CVPRW (GDUG) 2024, extended abstract paper / code |

|
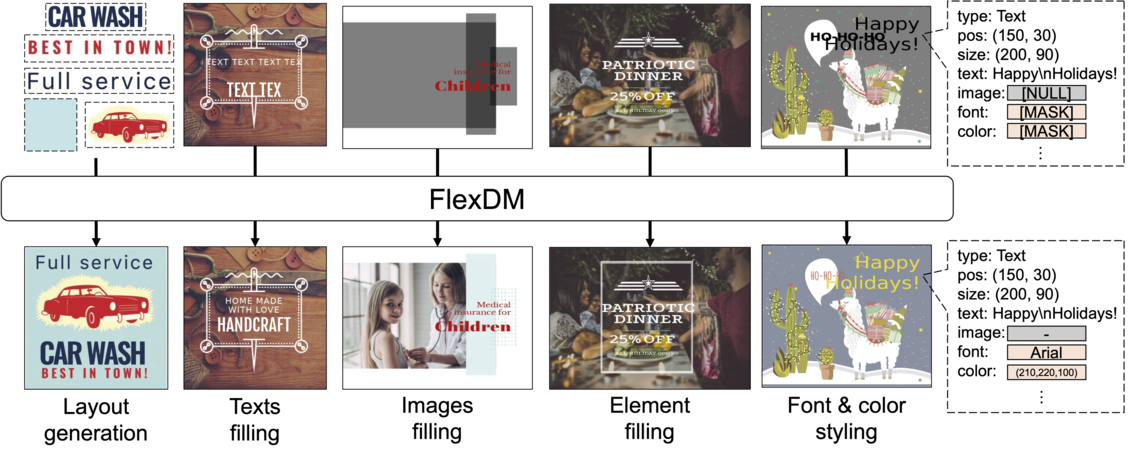
Daichi Horita, Naoto Inoue, Kotaro Kikuchi, Kota Yamaguchi, Kiyoharu Aizawa CVPR 2024 oral project / paper / code |
|
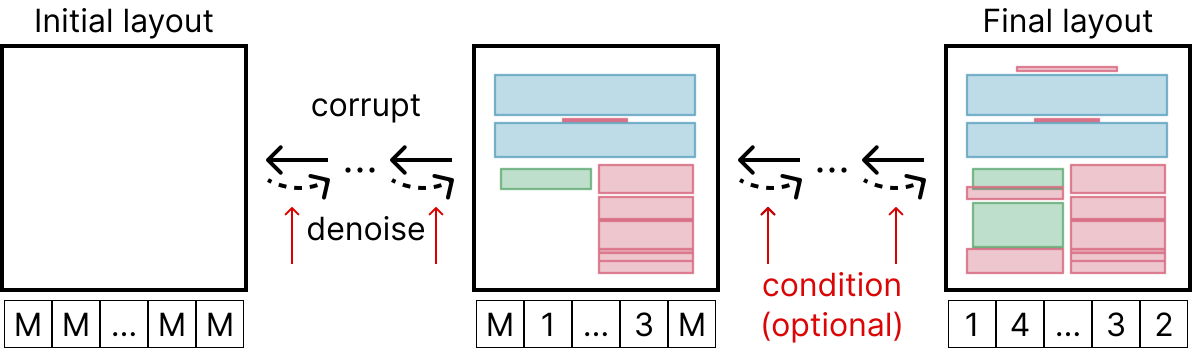
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi CVPR 2023 highlight project / paper / code |
|
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi CVPR 2023 project / paper / code |

|
Kotaro Kikuchi, Naoto Inoue, Mayu Otani, Edgar Simo-Serra, Kota Yamaguchi WACV 2023 paper / code & dataset |

|
Naoto Inoue, Toshihiko Yamasaki IEEE TCSVT 2021 paper / code & dataset |

|
Naoto Inoue, Daichi Ito, Yannick Hold-Geoffroy, Long Mai, Brian Price, Toshihiko Yamasaki CGF (proc. of Eurographics) 2020 paper / supp. / video |

|
Naoto Inoue, Daichi Ito, Ning Xu, Jimei Yang, Brian Price, Toshihiko Yamasaki CGF (proc. of Pacific Graphics) 2019 paper / supp. / video |
|
Ryosuke Furuta, Naoto Inoue, Toshihiko Yamasaki AAAI 2019 project / paper |

|
Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, Kiyoharu Aizawa CVPR 2018 project / paper |
|
Design: jonbarron |